Recherche & Développement
Apprentissage automatique et data science au cœur de notre R&D
L'IA chez Lizeo
Depuis sa création en 2009, Lizeo a beaucoup investi dans la recherche et le développement appliqué aux données massives que nous collectons et exploitons chaque jour.
Nous avons donc naturellement développé de nombreux algorithmes d’apprentissage automatique. La plupart sont l’implémentation concrète de publications scientifiques que nous défendons dans différentes conférences nationales et internationales suite à des travaux internes ou des thèses.
{kind=link}
{kind=link}
{kind=link}
- Une thèse sur la détection d’anomalies soutenue en mars 2018,
- Une thèse sur l’apprentissage multi-label pour l'annotation automatique en mars 2021,
- Un autre doctorant a soutenu en février 2023 sur la modélisation des thématiques,
- 24 publications scientifiques depuis 2014 dans SFC, EGC, Cap, IJCNN, KDD, ICML, MDAI et IEEE TNNLSE.
En ce qui concerne le sujet de l’Intelligence Artificielle, chez Lizeo, nous préférons le terme « Machine Learning ». Ainsi, nous développons des solutions « IA » depuis plus de 10 ans tant au niveau d’approches supervisées (c’est-à-dire nécessitant une base d’apprentissage étiquetée, c’est-à-dire fournissant pour chaque donnée en entrée un résultat attendu en sortie) que d’approches non supervisés (où l’algorithme tente d’extraire des schémas sous-jacents aux données non étiquetées).
Au niveau des algorithmes non supervisés, nous pouvons citer comme exemples :
La découverte de thématiques dans un ensemble de documents
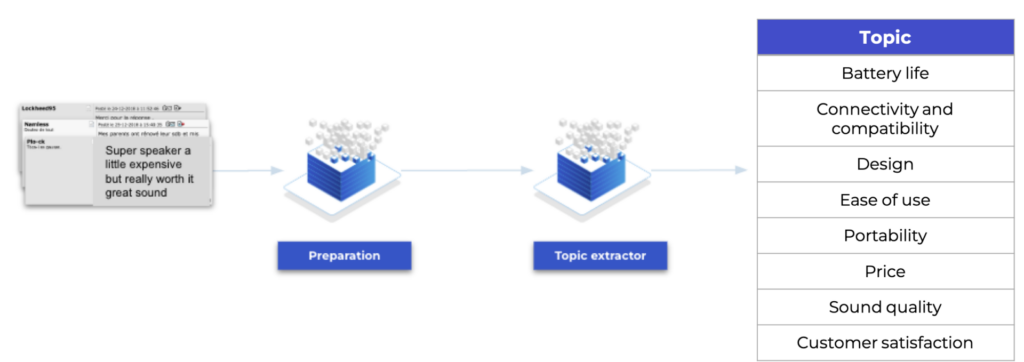
Pour cela, nous nous sommes appuyés sur les travaux initiaux du « Topic modeling » pour le faire évoluer vers une approche spécifique « Embedded Hierarchical Dirichlet Process (EHDP) – Palencia-Olivar et al. 2021 ».
La détection de prix aberrants dans une collection de séries chronologiques de prix
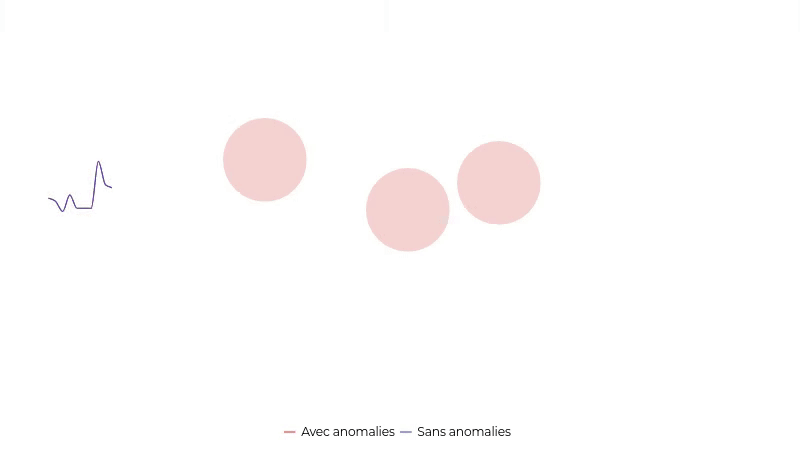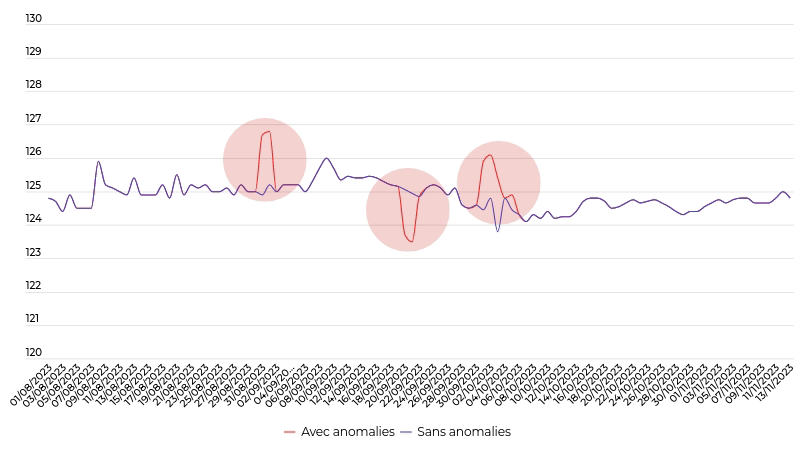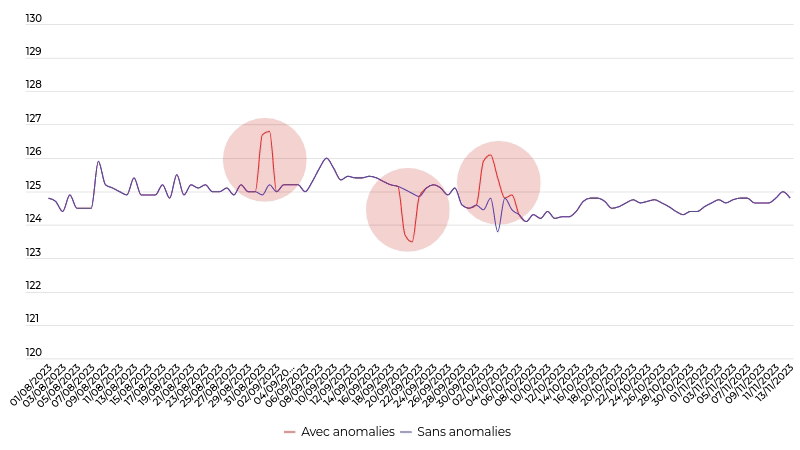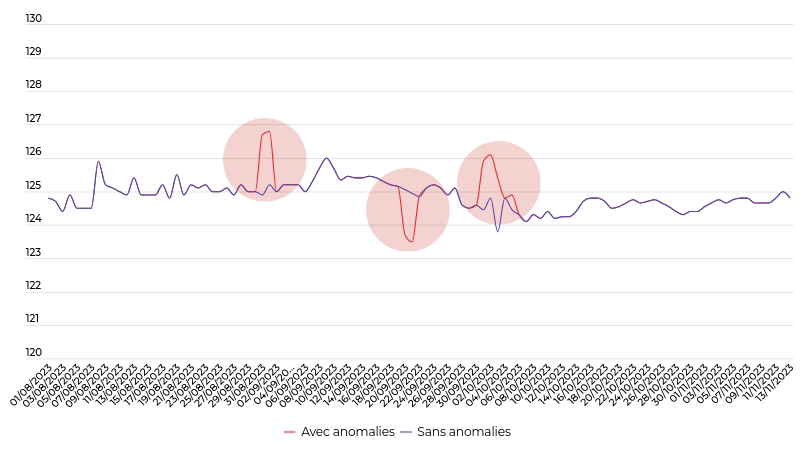
Nous voulions sortir des approches classiques qui supprimeraient les points globalement aberrants (zones en rouge) et pas forcément les points aberrants vis-à-vis des autres points (courbe bleue). En effet, le fait que la majorité des prix d’un même produit augmente n’est pas forcément une erreur, alors que si certains prix deviennent localement incohérents alors cela peut être le vrai problème. C’est pourquoi, nous avons mis au point le LADOP (Local Anomaly Detection based On Poison Model) qui a été publié dans la revue «IEEE Transactions on Neural Networks and Learning Systems» en 2021.
Au niveau des algorithmes supervisés, nous pouvons citer comme exemples :
La mise en correspondance de produits collectés sur des sites et une base référentielle
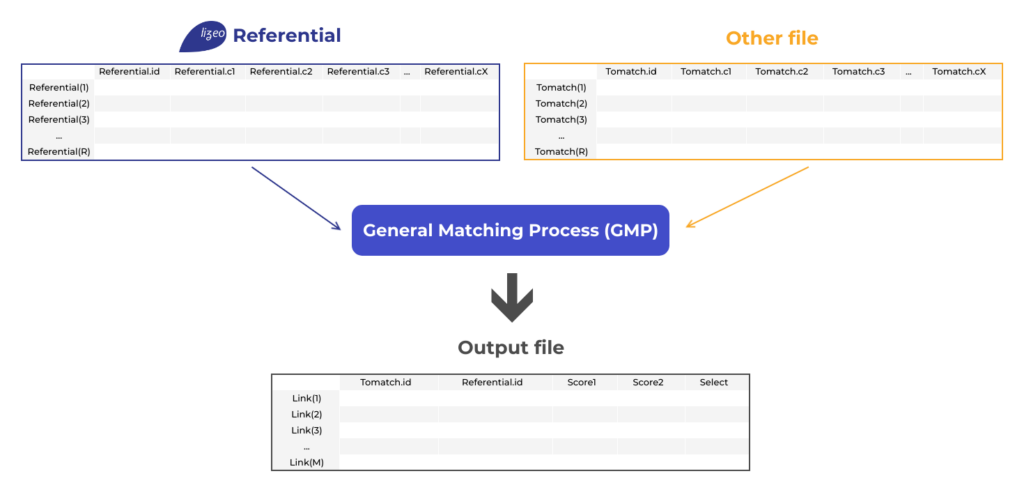
Un processus de mise en correspondance (matching) prend en entrée par une paire de flux de données nommés classiquement « referential » et « to match » à mettre en correspondance. Le résultat attendu est un flux contenant une liste de paires (tomatch.id, referential.id) avec des scores et la sélection potentielle (Vrai ou Faux) selon les valeurs des scores.
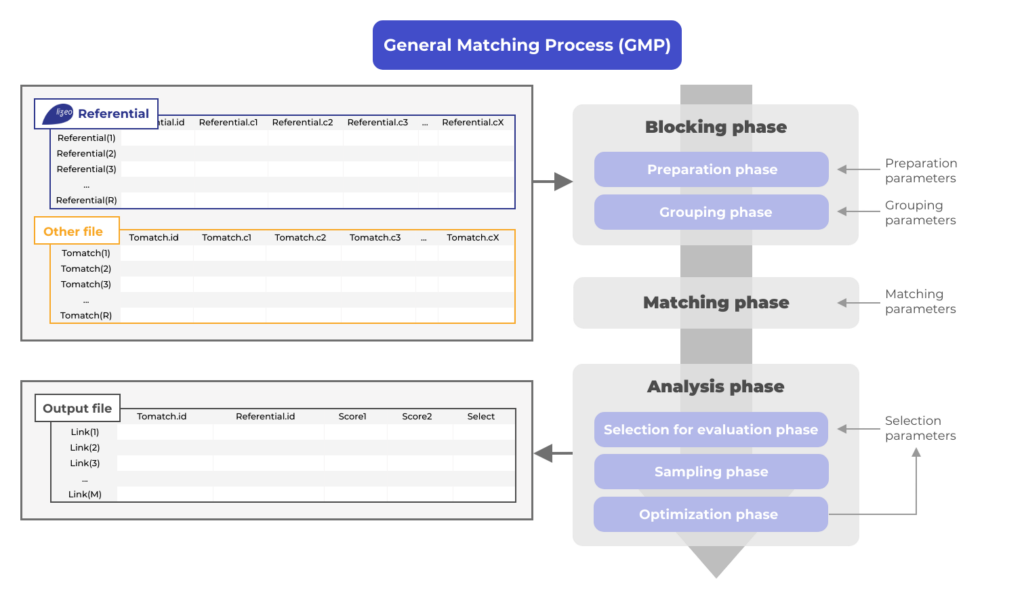
Pour cela nous avons développé notre propre algorithme de mise en correspondance généralisée que nous utilisons sur différents flux de données produits sur des sites internet.
L’analyse automatique des sujets et sentiments extraits des avis d’internautes
Cette approche nécessite donc une phase d’apprentissage s’appuyant sur une base qualifiée de textes avec des thèmes et tonalités associés pour créer les modèles pour la qualification.
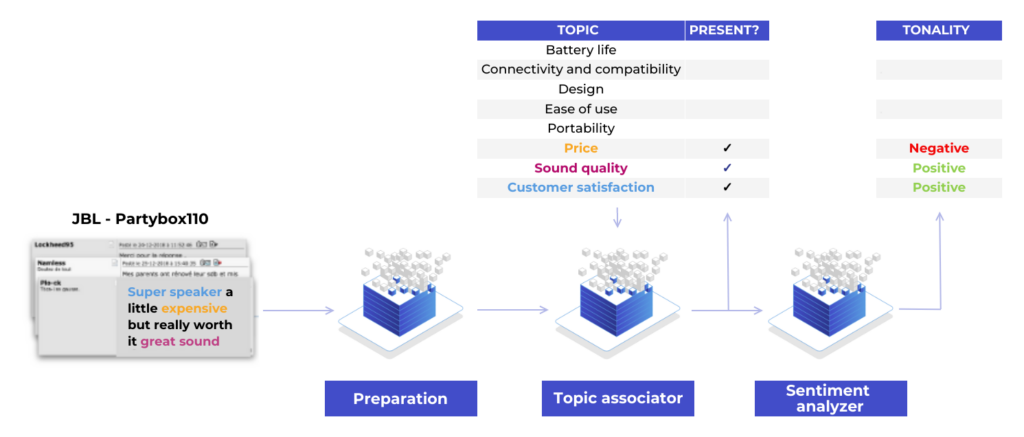
La phase d’inférence utilise simplement les modèles appris précédemment pour qualifier un nouveau texte.
Évidemment, l’explosion actuelle des très grands modèles de langages (comme ChatGPT par exemple) ne nous laisse pas indifférents. Nous les évaluons et les intégrons comme des briques complémentaires mais toujours avec une vision scientifique et donc critique.
Par exemple, pour la qualification automatique d’avis nous avons comparé dans plusieurs domaines les versions successives de ChatGPT, et les résultats sont parfois très étonnants. Il est donc primordial de tester systématiquement les modèles et de rester attentif à leurs évolutions.
Machine Learning & Data Science au coeur de notre R&D
ANTICIPER LES ÉVOLUTIONS DU MARCHÉ POUR AJUSTER VOTRE STRATÉGIE
- Des prix et des volumes du marché,
- Des comportements d’achat et des profils de clients,
- Des cycles de vie des produits.
DÉTECTER ET ANALYSER LES ATTENTES DES CONSOMMATEURS
- L’entité nommée (marques, produits, distributeurs, etc.),
- Les sujets,
- Les sentiments (positifs, négatifs).
Contactez-nous
Trouvons ensemble la meilleure approche pour répondre aux besoins de votre entreprise.